StudyMap — Day 1: AI That Knows What Your Students Don’t Know
A build journal. Ninety minutes in a cloud environment, one very specific problem to solve, and a few things that didn’t go to plan.
The Problem with AI in the Classroom Is the AI.
I spent eighteen years teaching GCSE Design Technology. I know what the exam board wants. I know what students get wrong. And I know that the gap between those two things — the specific, examinable knowledge a student is missing versus what a teacher has time to address — is where students quietly fall behind.
The obvious answer, on paper, is AI. Point it at student progress data, let it identify gaps, have it surface the right resources. Simple enough. Except every AI tool I’ve tried fails in the same two ways.
First: accuracy. GCSE DT has precise definitions. Primary vs. Secondary Recycling. The 6Rs. Material property tables. These aren’t things you can approximate — they’re examinable. Off-the-shelf AI, trained on the general internet, gets these wrong with complete confidence. That’s not a tool. That’s a liability sitting in front of a Year 10 class.
Second: compliance. Student data can’t go into ChatGPT. It can’t go into any cloud AI tool you don’t fully control. GDPR isn’t an inconvenience — it’s a hard constraint. Any system that touches student performance data has to keep that data inside the school environment, full stop.
“Generic AI doesn’t know AQA from OCR. And even if the output were perfect, you can’t paste student data into it without a compliance problem.”
So today I started building something that solves both. A system grounded in the actual exam board specification — not a summary, the real thing — and architected so student data never leaves school. Here’s what day one looked like.
Moving Beyond Chatbots. Building an Agent That Can Actually Act.
The first decision was the platform. For a system that needs to reason over a knowledge base, use external tools, and make decisions — not just generate text — you need an agent architecture, not a chatbot. I went with Google Cloud’s Vertex AI Agent Platform, which gives you MCP servers, a proper RAG engine, and a knowledge corpus as first-class components rather than bolted-on extras.
Getting this running is straightforward enough. The more interesting question — the one that dominates the next thirty minutes — is how you make the AI actually accurate about GCSE DT content specifically. That’s a knowledge problem, not a model problem.
The Table Problem. And Why Standard AI Gets It Wrong.
Retrieval-Augmented Generation — RAG — is the approach of grounding an AI’s answers in a specific document set rather than general training data. Feed it the actual AQA specification, it answers from the specification. Hallucinations drop dramatically because the model is working from a source of truth you control.
The catch is that educational documents are full of tables. Material property charts. Specification matrices. Assessment criteria grids. A standard text chunking approach shreds table structure completely. The AI ends up with fragments that have lost their context — it might know that “polypropylene” appeared near “flexible” somewhere, but it’s lost the relationship between them.
If an AI loses the structure of a specification table during indexing, it reconstructs plausible-sounding answers that are technically wrong. For exam content, “plausible but wrong” is the worst possible outcome.
The solution is Document AI’s Layout Parser — a chunking strategy that understands document structure and preserves table relationships. It’s slower to set up, but it means the knowledge base actually understands what it’s been given.
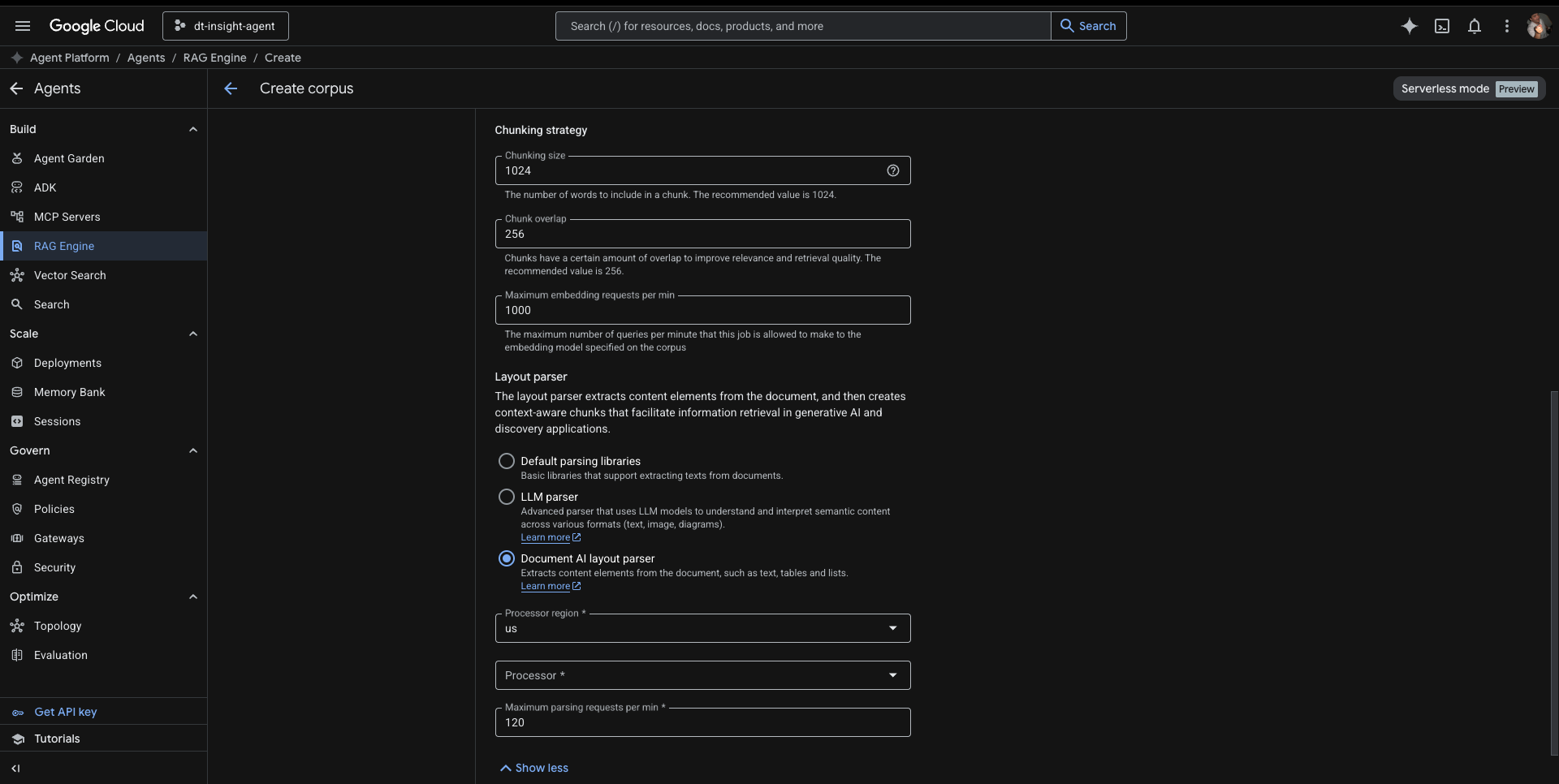
Not a Prototype. A Codebase.
There’s a version of this project you could build entirely through the Google Cloud UI — clicking through menus, configuring options, deploying without touching a terminal. I didn’t do that, and I wouldn’t recommend it for anything you intend to maintain or hand over to a client.
Instead, I used the Agent Starter Pack to scaffold a proper codebase in Cloud Shell Editor. Structured file tree. Version control from the start. Configuration as code. It takes longer on day one and it’s the right call for every day after that.
This also matters for the school context. A tool that informs decisions about student interventions needs to be auditable. You need to open it up, explain what it’s doing, and update it when the specification changes. A no-code prototype doesn’t give you that.
The Bit That Didn’t Go to Plan.
Somewhere around the forty-five minute mark, things got interesting. Initialising the RAG corpus in the default Spanner-mode database configuration hit a regional capacity limit. Permission denied. Quota exceeded. The kind of error that looks alarming if you haven’t seen it before.
It’s worth being honest about this in a build journal because it’s representative. Cloud development is not a straight line. Infrastructure constraints, regional availability, API permissions — these aren’t edge cases, they’re the job.
“The error looked like a wall. It was actually just a signpost pointing to a different route.”
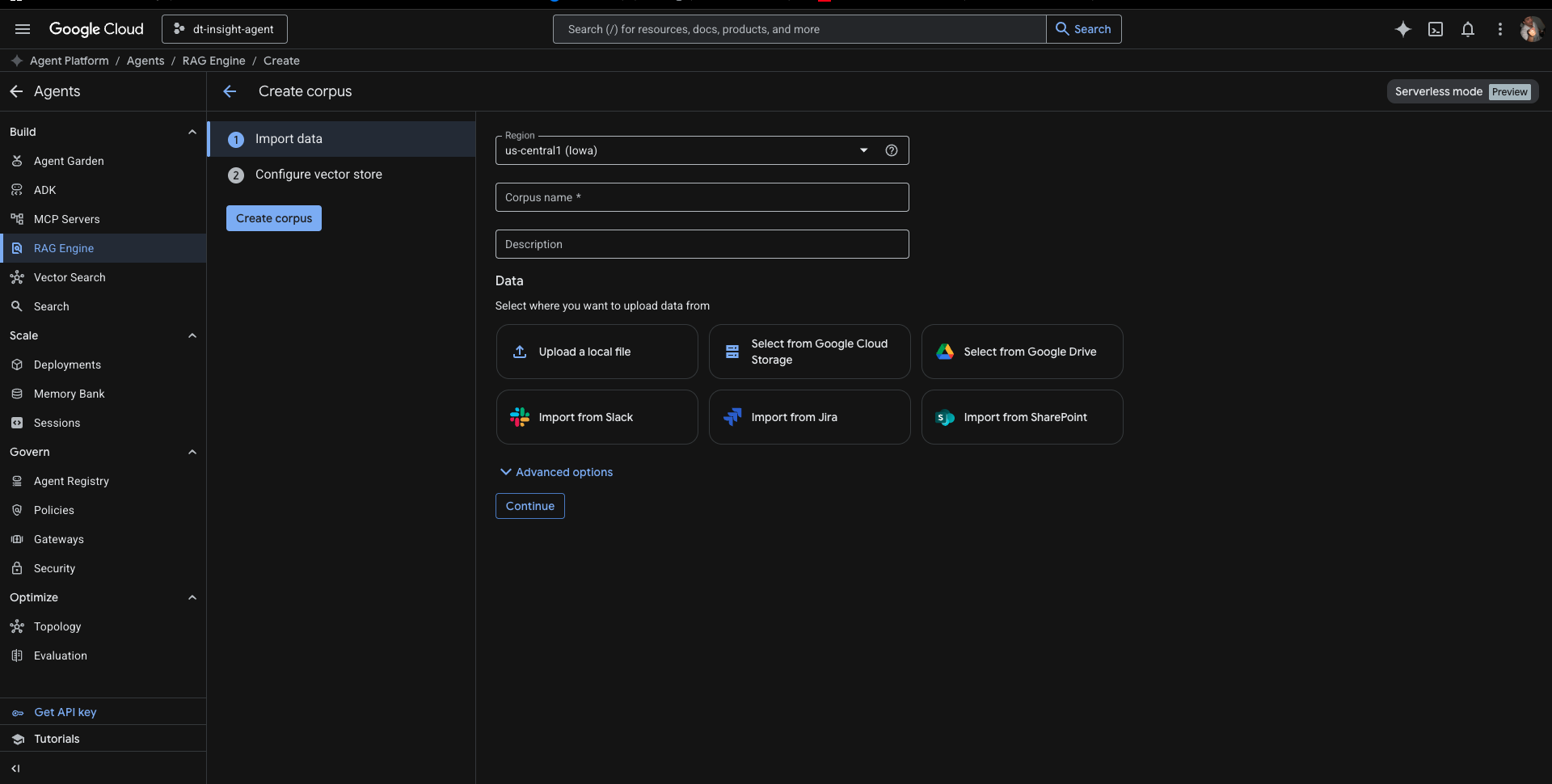
The fix was switching to Serverless Mode in a different region. Corpus came up cleanly. Build continued. Total time lost: about twenty minutes. Having worked through that constraint in development means I know the answer when it matters in a client’s environment.
Student Data. How It Stays Inside.
Before the session wrapped, the privacy controls were configured. This is worth a moment because it’s easy to list it as a feature and not explain why it’s actually the structural argument for a system like this.
Student PII is anonymised at ingestion. Identifiable data never leaves the school environment — not because of a settings toggle, but because the architecture doesn’t create a pathway for it to. For schools, this is the conversation that gets you in the door. For finance and healthcare, it’s the same conversation with different regulators.
When a teacher reviews an AI-generated resource before it reaches a student, they’re not just approving content quality — they’re the last human check in a pipeline designed with compliance as a constraint, not an afterthought.
The Foundation Is In. The Interesting Work Starts Tomorrow.
By the end of ninety minutes, the knowledge base is live. The spec is indexed. The agent has a brain — now it needs logic. Days two through twenty are where the system actually gets built:
Student progress analysisAnonymised performance data mapped against specific syllabus points. Not “this student struggles with sustainability” — “this student has a gap at 3.2.1b.”
Resource retrievalBefore any generation happens, the system searches the school’s existing resource library. If something appropriate exists, it surfaces it.
Gap-fill generationWhere no resource exists, the agent drafts one. Spec-accurate, not generic. It queues it — does not publish it.
Teacher review gateEvery AI-generated resource sits in a review queue. The teacher approves, edits, or rejects. Nothing reaches a student without explicit sign-off.
Nineteen days left to build it, test it, and document it well enough that someone other than me can run it.
- Gemini 1.5 Pro agent initialised
- GCSE DT Sustainability spec indexed
- RAG corpus live via Document AI Layout Parser
- Anonymise-first privacy controls configured
- Student performance data analysis pipeline
- Existing resource library integration
- Gap-fill generation with spec grounding
- Teacher review interface and workflow
- End-to-end testing
- Deployment and handover documentation